We have talked elsewhere (see reference 1) of building a vocabulary from the decomposition into primes of the product of the values of the cells of the interior of soft centred patterns –values which are small integers. Using, for example, the prime number ‘3’ to code for the colour ‘green’, with the amount, the intensity of greenness being the power of 3 in that product, typically another small integer, say less than 20 or so.

So in the yellow pattern, the soft centre power of 3 is 5, in the blue 2 and in the grey 0. The green is left as an exercise for the reader. We may add an element of normalisation to the mix, to allow for the size of the pattern.
The signal, as it were, from any one element of the host layer object, apart from the identity of the pattern itself, is the sequence of powers of the ascending sequence of primes, a sequence which rapidly becomes a sequence of zeroes.
Remembering in this that we are doing rather more than coding for green, we are trying to build the subjective experience of green, in a context (that is to say the interior of a brain) where colour, in the ordinary sense of the word, is not available. Is it not enough to know that the prime ‘3’ stands for green, refers to green. It has to be green.
Shapes
Another approach, one which might be thought to be both rather less vulnerable to signal noise and rather less contrived, would be to use shapes, of the sort illustrated below. Each soft centred pattern contains an idealised version of a shape from a vocabulary of shapes, coded by having low cell values representing black and high cell values representing white, at least roughly speaking as we allow a certain amount of noise. Note that we use the word ‘shape’ in preference to the more obvious ‘pattern’ as we have already used pattern in the definition of our layer objects.
Neural networks can readily be trained to recognise such shapes, so no doubt the neurons in brains could be so trained.

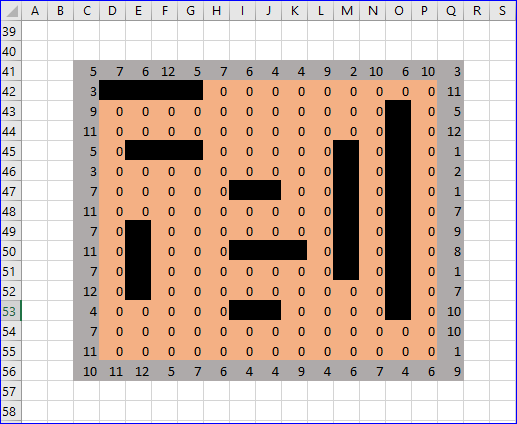
This first group of shapes works on a two by two grid. We allow zero, one or two, white bars, horizontal or vertical, on a black background, giving us a total of 10 shapes. With the double blue lines around the squares designating the perimeters of the soft centred patterns. Squares seem the natural shape for this sort of thing, although we might want to have squares of more than one size, with bigger squares admitting more shapes.
The idea of the restriction is to make identification of a shape easy and reliable. While if we had allowed any permutation of the white squares we would, of course, have had rather more shapes in our vocabulary.
But, as it is, we could allow two additional qualifiers, one for intensity and one for goodness of fit. Given that each cell of the interior can take an integer value roughly in the range [0 10], with low value being black and high value being white, we could take the average to give us a measure of intensity. While goodness of fit would be about how clear it was that we had one shape rather than another, perhaps some combination of distance to the most likely shape and distance to the next most likely shape. These two numbers are not completely independent – with, for example, an intensity of high value having to be the bottom left shape and an intensity of low value having to be the bottom right shape – but they are reasonably so. We could, for example, have perfect fit with fairly low intensity. But for the moment, we stick with just intensity, also in the range [0 10], for information coding purposes.

This second group of shapes works on a three by three grid, which will need better resolution than the two by two grid. The rule here being that we allow any number of adjacent vertical bars and any number of adjacent horizontal vertical bars. The illustration above shows most but not all of the permitted possibilities.
The idea of the restriction is, again, to make identification of a shape easy and reliable. While, as before, if we had allowed any permutation of white squares we would have had a lot more shapes.

This illustration show some shapes not presently permitted. The left hand three because they involve parallel bars which are not adjacent, the right hand two because they are made of elements which are not complete bars. It is probably not important for present purposes exactly what these rules are; what is important is that we have around 30 shapes in all to play with – as it happen, roughly the number of letters in European alphabets, accents aside.
How does this compare with the prime number approach?
As things stand, we have ten shapes in the first illustration and fifteen in the second, with some missing. Rounding to a convenient power of 2, we allow 32 altogether. 32 patterns plus intensity.
If we look at the prime numbers to be found in the product of the interior values, we might have the first six prime numbers, but quite a lot of room for powers, with the product of the interior allowing quite a large power of 2. We could say that this power could take the same role as intensity does with the shapes.
Thinking about the coding capacity of the two approaches we appear to have it that shapes carry more information in small patterns, primes in large patterns. Shapes score initially as they do not discard position, while a prime scores just the same wherever it appears in an interior, but lose in the long run as they do not make use of the extra space – not unless, that is, we add to the repertoire of shapes, which might get messy.
Primes have their attractions. First, they are a fundamental part of number. Fundamental in a way that shapes of this sort are not. We can rely on aliens knowing about prime numbers, even if their eyesight was not too good and they were not strong on shapes. Second, we can aggregate the primes from the interiors of adjacent elements and get a sensible average for the whole. We cannot aggregate shapes in this way.
However, shapes are good in that we have more of them available than we are likely to have primes. Are good in that training neurons on shapes seems a better bet than training them on number theory.
But they have their detractions. First, one cannot mix shapes within an element in the same easy way as one can mix prime numbers. That said, while one cannot mix shapes within any one element, there is no difficulty about mixing shapes across the elements of a layer object, so perhaps this is not a serious difficulty. Second, we may have difficulties with small numbers of rows doing both 2-based patterns and 3-based patterns.
Both primes and shapes are bad in that they have no obvious connection to the uses to which we propose to put them. The relation between a shape and its use to code up information – we might, for example, have some shape stand for the colour red – is going to be arbitrary. But perhaps that is inevitable; there is no natural way to code for red other than by having a patch of red, an option which would not be helpful in the context of the brain – there being no light in the interior of the brain, never mind machinery for telling red light from green light, machinery which would seem, in any case, to be close to the trap of the infinite regression of the homunculus.
A cellular approach?
In the foregoing we have gone for a limited selection of shapes defined on 2-grids and on 3-grids. As noted above, an alternative would have been to go for the individual grid points or cells, perhaps just using the one 4-grid for simplicity, with our brain recognising all 16 isolated cells, plus one for blank, and most if not all combinations.
It would then be possible to decompose any larger shape into its constituent cells, with the larger shape being a mixture in that sense. But without the power of the primes as the powers would always be 0 or 1. We could not mix in the proportion 2:1.
A segmental approach?
If we were to suppose quite large patterns, we would be able to do shapes in a way that came close to primes.
In the illustration above we have a number of bars: one 4, three 3’s, two 2’s, one 7 and one 11. Which gives us something very close to our primes, while reminding us of letters from an alphabet.
A frequentist approach?
Yet another approach would use a smooth and monotonic map from the frequencies of visible light onto some range of frequencies available to oscillations of activity of ensembles of neurons, an approach which would burn up a lot of layers in our data structure, which has been organised by frequency into layers. We have already played the frequency card.
Nor is it as natural as it might seem, with the frequencies of inbound light being mapped onto the firing rates of the different kinds of rods and cones on the retina. Frequency does not get past the retina. Ears are slightly better in that inbound sound is, roughly speaking, decomposed into quite a lot of constituent frequencies, rather more than the three or four of light, before being passed onto the brain.
But for this very reason, sound would be far too greedy of layers to be practical at all. And even without that, one would still have the problem of what to do with those senses, certainly taste and smell, which are not organised by frequency. Not sure about touch, which quite possibly does have a frequency angle, the frequency of the vibrations and oscillations resulting from rubbing one’s finger along a rough surface.
Conclusions
We have presented an alternative to coding up our data in the elements of layer object with prime numbers – which last, while reasonably effective, seems rather far fetched in the context of the brain.
But there are plenty of other ways to do this sort of thing. So we will continue to work on what might work best.
References
Reference 1: http://psmv3.blogspot.co.uk/2017/03/coding-for-red-and-other-stuff.html.
Group search key: srb.
No comments:
Post a Comment