We offer here two modifications to that scheme and one observation, which we believe will be helpful when we come to describe real world scenes – and other conscious content – using this machinery.
Opening up layer objects
One of the rules of a shape net was that the external perimeter of a layer object was a closed loop. Another was that the shape net defined the parts of that layer object by means of more closed loops, subsets of that shape net. Another was that shape nets were maximal with regard to the blue connections, for example in Figure 1 following.
 |
| Figure 1 |
 |
| Figure 2 |
Have we relaxed it to the point where a part is defined by the presence of a texture net, a maximal object with regard to the green links, rather than by the presence of a bit of shape net? Texture nets which are usually connected by at least one brown link to a bit of shape net? An observation which gives more weight to the brown links than hitherto, with Figure 1 having described them as having low value. Without going into the question here, we suspect that most parts will have rather more than a texture net or a brown link to propel them into existence, they will have loops. But see Figure 5 below.
While from ‘missing’, we associate to other parts of other images which are sometimes missing from consciousness, in the case of people, for example, who see the left hand sides of objects but not the right hand sides – a condition for which hemianopsia might be the technical term. What is their experience?
 |
| Figure 3 |
We do require the texture net of the left hand object to be tied to its shape net, if only to distinguish it from the background, for which see below.
Generally speaking, this relation of occlusion will put a partial order on the layer objects of a layer – but not always as there will sometimes be perverse objects which are in front of themselves, which wrap around and occlude themselves, an event not allowed for in the rules for partial orders.
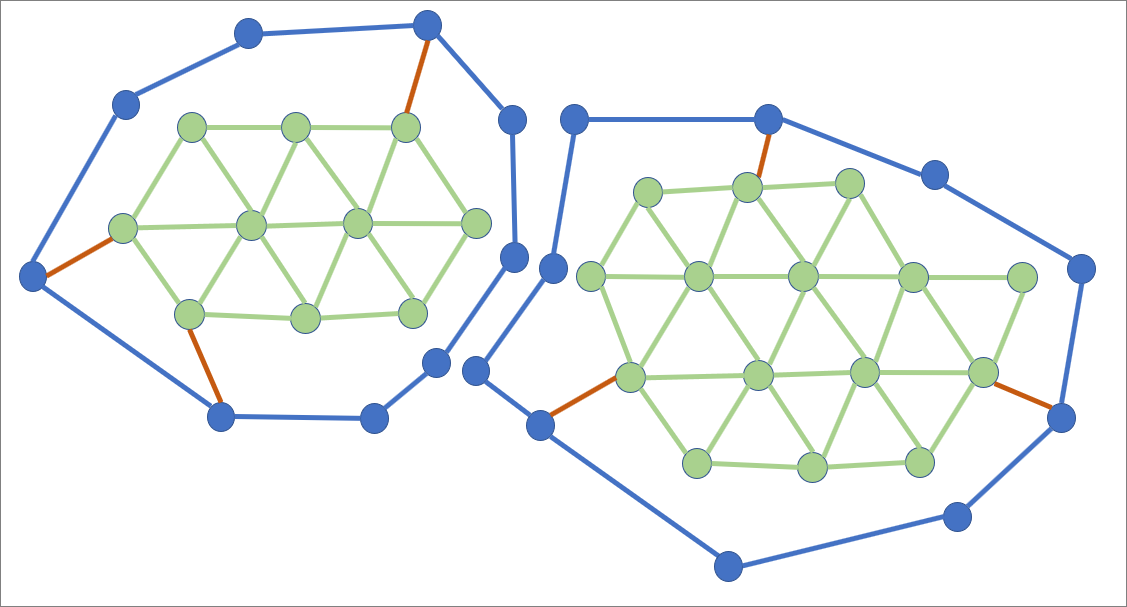 |
| Figure 4 |
In the real world, the sort of ambiguity which can often be sorted out by small head movements giving slightly different perspectives. What gets in the consciousness may well be the perceptual result of those head movements, integrated over some short period of time, rather than some instantaneous image taken more or less directly from the retina. And probably needing more than one layer for their proper expression.
 |
| Figure 5 |
 |
| Figure 6 |
 |
| Figure 7 |
Do we want all these fragments of shape nets to count as layer objects? Should we just regard those fragments as noise, not worthy of conscious attention?
We suspect that the answer will lie in-between, in the sort of judgement call that deep learning neural networks are turning out to be rather good at.
The background
Every maximal bit of texture net defines a part of a layer object. Every maximal bit of shape net defines a layer object. Most layer objects will be defined in both ways.
However, we might group those texture nets which are not connected (by brown links) to a node of a shape net up into something we call the background. Most often there will either be no background, or a background made up of just one texture net, in which last case the background is special sort of layer object.
 |
| Figure 8 |
Note that the geometry of this particular background is more mixed than that of the layer object in the middle, expressing the fact that the texture of the background is more mixed than that of that layer object. Perhaps the simple regular pattern of the interior of the layer object codes for something simple like a uniform, primary colour. A coloured ball flying across the garden.
It may also be that the background comes in more than one piece, in which case they may be connected together by means of column objects, making use of a second layer object on a second layer for the purpose.
One might take the theatrical analogy further, in the way of reference 2, from the days of LWS-W, and use this machinery to add a foreground, that is to say the stage on which the scene is played, and flats to the side. But this would not need any more new machinery, any more new rules.
 |
| Figure 9 |
 |
| Figure 10 |
 |
| Figure 11 |
What are these rules for?
We need to remind ourselves from time to time that all these rules, while interesting in themselves, in their own right, are not the main point. What is important here is that the decomposition of the layers of LWS-N, of the layers of experiences, into layer objects, parts and textures is what drives the organisation of waves and vibrations of neural activation around and across those objects, parts and textures, waves and vibrations which are hypothesised to amount to what we experience as consciousness.
The layer objects, parts and textures describe in graphical terms, graphics which are written into the neurons of our patch of cortical sheet, what we experience in terms of brain waves – some of which may turn out to be detectable, separable from all the other brain waves swinging around the brain.
Moving layer objects
On a parallel track, we have been thinking about how objects in consciousness might move, something which is clearly needed in the case of vision – if only for the fast detection of potential prey and of predator animals – and is probably needed in other modalities. Or perhaps we will have it that the existence of machinery for motion in the case of vision has just been leveraged by the other modalities.
A problem which is solved in the cinema by having a sequence, perhaps as many as 50 to the second, of static images, one presented on top of the other, as it were. A solution which we do not favour here. There will be more amount this in a post to come.
 |
| Figure 12 |
The blue dots stand for the cell bodies of the neurons, in their place on our bit of cortical sheet. Their synapses, junctions, dendrites and axons are implied rather than shown.
Such a node can have a continuing existence but an evolving population of constituent neurons. The continuity is expressed by the fact that if we look at the node at two successive points in time with only a short interval between them, there will be a lot of neurons which are in the node at both points in time; most of the neurons will be in the node at both points in time. So while the neurons do not move, a node can move if its constituent neurons evolve in a systematic way.
And the links can move in a similar way.
In this way, our layer objects can move while having a continuing life. We are not having to create them anew, in the way of the successive frames of a cinema film.
Previous work
The present note addresses in LWS-N much the same issues that are addressed by references 2 and 3 in LWS-W, the workspace defined in array rather than graph terms. There is some overlap with reference 4, although this last goes on to talk about linking layer objects together into composite objects, which we have yet to address in the new world.
We feel that the new world, the new scheme is less contrived than the old, and maps more easily onto the neural substrate.
Foreground has, however, been dropped.
Conclusions
We have presented a few adjustments to the scheme introduced at reference 1. Work in progress.
References
Reference 1: http://psmv3.blogspot.co.uk/2018/01/an-introduction-to-lws-n.html.
Reference 2: http://psmv3.blogspot.co.uk/2017/06/on-elements.html.
Reference 3: http://psmv3.blogspot.co.uk/2017/07/rules-episode-two.html.
Reference 4: http://psmv3.blogspot.co.uk/2017/08/occlusion.html.
Group search key: srd.
No comments:
Post a Comment