Contents
- Introduction
- Activation processes
- Sinks and sources
- Varying the capacity of the channel
- The original column object
- Generalising the links
- What is the length of a link?
- Parts of a whole, sensed but not seen
- The wrong path?
- Descriptive layers
- Things we have not done
- Conclusions, Abbreviations, References
We have our layered data structure, our LWS, and we have defined layer objects and their parts on that data structure. We have defined composite objects, that is to say, linked together layer objects which are juxtaposed, next to each other in a special way. See, for example, references 6, 7 and 9.
The idea has been – and remains – that we need to be able to link together layer objects which are not juxtaposed, often not even on the same layer, different layer objects which represent different parts or different aspects of the same thing out it the real world – quite often a real world object of the ordinary sort, something you can see, touch or move about. We will use different layer objects on different layers to carry different sorts of information about the same object. For example, on one layer we might have information about the visual appearance of some object, while on another we might have information about its smell. Or where we last saw it. Or whether we like it or not, our emotional response to it, this last often being a convenient shorthand guide to action.
Or we may have layer objects which are linked together, not because they are the same or about the same thing, but for some other reason: perhaps there is something that is common between them, and the UCS has used that something to leap from one to the other.
And connecting all this stuff up in the conscious experience is our version of what is often called the binding problem, introduced at reference 8. Over the months, we have come up with a variety of wheezes to do this linking, some properly documented, some not. Wheezes which need to be plausible in our world of neurons, and which should probably not use the sort of identifiers usually used in databases on computers for these purposes, things like national insurance numbers (for example, ‘YC763982B’) or NHS numbers (something with the format ‘987 654 4321’).
An early wheeze (see reference 1) was the column object, a column of high valued cells through all the layers of LWS, in contrast to the layer object, contained within a single layer. The idea was that all the layer objects which included the column, or more accurately included the cell which represented the column on their layer, were linked and together constituted an extended object.
Another wheeze (see reference 2) was the soft centred pattern, with the pattern being the pattern of values taken by the rectangular perimeter of the rectangular element of a part of a layer object, with, at that time, parts being made up of such rectangular elements. Not only did the pattern serve to define the parts of layer objects they also served, in some part, as identifiers. Parts in different places, defined on the same pattern, were linked.
More recently we have thought in terms of layer objects on different layers, but which share a sufficient chunk of boundary (the new word for perimeter, defined at reference 6), as being linked.
Then we thought in terms of matching curious shapes on the boundary, for example the growth on the right hand side of the right hand object in Figure 1 below. If two layer objects share such a curious shape then they are linked; a device similar, for identification and linkage purposes, to the soft centred pattern.
As well as being a little contrived, at least in the context of small sheets of neurons, all these wheezes relied on the links being defined in the data, a reliance motivated by the thought that LWS was all there was as far as consciousness was concerned. It all had to be there.
Activation processes
But did it? LWS is brought to life by activation processes, with consciousness being the result of the action of those processes on the data. Activation which, inter alia, will run around the boundaries of layer objects and sweep across their interiors.
The point of binding being to achieve activation of things which are bound together at more or less the same time.
The activation processes and their flow around LWS is something which is built by the compiler, and presumed to be expressed in the synaptic connections, rather than the activity, of the underlying neurons.
Which leads to the thought that if the compiler is using its knowledge of what is linked to what when it makes those synaptic connections, what further need is being met by expressing those same links in the data? This is very much part of what we were getting at in the introductory remarks at reference 6.
And part of the answer is belt and braces.
Sinks and sources
 |
| Figure 1 |
In the snip above, using the surround convention introduced at reference 6, we suppose the left-hand and right-hand layer objects to be on different layers. But we want to link them, for one reason or another.
Then the blue and yellow pattern – the high valued cell surrounded by low value cells – and there may be more of these last, but not less than those shown here – in the middle part of the left hand object is the sink, while that in the middle part of the right hand object is the source, with both these patterns being required to be inside a region, that is to say the interior of a part of a layer object, excluding here both background and foreground. The sink and source are connected by a vertical column, running between the two layers concerned – noting here that in Figure 1 we have lined the sink and source up, the sink is vertically above the source. Then some of the activation which flows over the sink is diverted to the source.
 |
| Figure 2 |
We suppose here that the blue boundaries of the objects involved are orthogonal to the plane of the page – so we do not get to see much of them. In the case that the section happened to run along a boundary, we would get to see rather more.
So, at the upper layer we have a three part layer object, viewed in section and outlined in black (the Excel outline feature for a cell selection), plus two bits of background, in green. While at the lower layer we have two one part layer objects, plus two bits of background and two bits of foreground. For these last, see reference 7. With the distinctively patterned column object running between them.
As it stands, this definition is symmetrical. Such a pattern in a layer object is a sink if the level of activation of that containing layer object is higher than that of the layer object at the other end.
An alternative would have been for activation to flow from the higher layer to the lower layer – alternative which would exclude the linkage of two objects on the same layer, described below.
But, for the moment, we do say that a column objects links exactly two layer objects, one at the higher layer and one at the lower layer. We are not allowing intermediate connections.
These new links, these sinks and sources, are expressed both in the values of cells, in the activation levels of neurons, and in values of synapses, with our snips from Excel showing the former but not the latter. To that extent it is no longer true that all our data is expressed in the values of the cells of our layered data structure, our LWS.
Varying the capacity of the channel
Furthermore, we might vary the size on these sinks and sources, we can vary the speed and volume with which activation is moved about, a possibly useful feature not supported by the wheezes, which were binary, present or absent, at least as they were originally defined.
 |
| Figure 3 |
Furthermore, we do require the blue core to be the same through all the layers through which the column object extends. We are more relaxed about the yellow wrapper, provided only that it does wrap.
The original column object
 |
| Figure 4 |
What was being linked was the host layer objects and what we were saying was that the three objects, the three images so linked, were all aspects of the same real world object, the same object in which UCS was taking an interest, for one reason or another. So top might be smell, middle might be vision and bottom might be touch. In which it seems likely that there are going to be more parts to the square centimetre in vision objects than there will be in smell and taste objects. Vision is naturally structured, open to triangulation, in the a way the smell and taste are not – or at least that is our guess.
And, looking ahead, one or more of these three objects might be more or less tantamount to text, to language, albeit of a fairly simple sort.
The column object does not touch the other layers where it goes through either background, foreground or some dead bit of space, a hole, none of which can be linked in this way, which do not count.
Part of the price is the small hole punched through all the layers. A bit like having lots of blind spots, compared with just the one on each retina.
 |
| Figure 5 |
An alternative would have been to have column objects which run between two layers and bind to whatever is at the two ends, perhaps by not allowing them to pass through regular layer objects at intermediate layers. We prefer the first solution, the stronger solution.
Generalising the links
So far we have talked about linking layer objects which are about the same thing, some thing for which there is, as it were, a single entry in UCS. Now we talk about linking layer objects which are not about the same thing, but links which express some relation or other between the things which the two layer objects stand for.
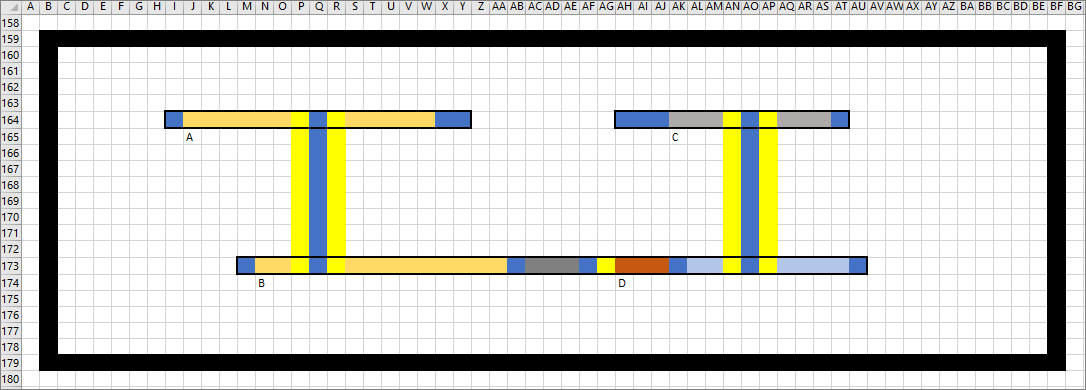 |
| Figure 6 |
The top left layer object (A) and the bottom left layer object (B) represent, in some sense or other, the same object of interest to the UCS. The same is true of the top right layer object (C) and the bottom right layer object (D). With C and D being linked by being part of the same composite object CD, and with that composite object as a whole expressing what sort of a link, what sort of a relation we have between A and C.
And we would say much the same thing in the case that A and B were not on the same layer, while noting that in this case it would be more likely that A and B were versions or aspects of the same UCS thing.
Note that the relation (say R) will not always – or even usually – be such that R(A, B) implies R(B, A) or that R(A, B) and R(B, C) implies R(A, C).
What is the length of a link?
Chaining, we can make links of this sort of more or less arbitrary length, with, other things being equal, long links being weaker than short links.
 |
| Figure 7 |
In the middle, we have it that object C is connected to object E through one column object and one order border. Where it is the blue and yellow order border which both separates and connects object D and object E, making the composite object DE.
While in the rightmost, we have it that object F is connected to object I through two column objects and three order borders.
Without presently going so far as to put a partial order on link distances, and in so doing quite possibly distinguishing the direction in which these various obstacles are overcome, it is clear that the distances mentioned are increasing. The second object is getting to be further away from the first object. In the first configuration, we are talking about two versions, two aspects of the same thing, while in the third the relationship is much more remote.
All this will be reflected in the behaviour, in the flow of the activation processes across the data structure, across LWS.
Parts of a whole, sensed but not seen
 |
| Figure 8 |
 |
| Figure 9 |
Alternatively, we might not be vague at all, we might know full well what the shape of the real world object is, even if we can’t see it.
 |
| Figure 10 |
But, either way, how do we know that the function of the container objects is indeed to contain? Can we say that these containers are on visual layers, albeit low activity layers, only just present in consciousness, and by default the connections are those of parts to wholes? Do we need some experimental evidence, evidence which is unlikely to be forthcoming any time soon? We shall return to this point shortly.
The wrong path?
We have linked layer objects together. We can have those objects activated, in consciousness, at more or less the same time.
But we have yet to say anything about the link. So we now give some suggestions about the sort of things one might want to say about the link and the parts or objects at the ends of link. Leaving aside for the present the question of where this stuff might be put and how it might be expressed.
Is it a link between one object and another, one part and another, or something in-between? We identify four things which might be linked:
#OBJUP
#PARTUP
#OBJDOWN
#PARTDOWN
Where ‘UP’ refers to the object or part on the higher layer, ‘DOWN’ to the lower layer. Bearing in mind that either or both of the objects involved might only have one part. A formulation which only works in the case that the column object links an up object to a down object, through an intermediate object holding some description, in these terms.
We then allow predicates involving those things. For example:
contains(#OBJUP, #OBJDOWN)
describes(#OBJDOWN, #OBJUP)
partof(#OBJDOWN, #OBJUP)
partof(#OBJUP, #OBJDOWN)
same(#OBJUP, #OBJDOWN) – the two things are identical. Represented by the same object in UCS.
same(#OBJUP, #PARTDOWN)
samekind(#PARTUP, #PARTDOWN) – the two things are the same kind of thing. Different instances, different representatives of the same object class, perhaps a single something n UCS, perhaps a single something somewhere in memory.
notsamescene(timeplace(#OBJUP), timeplace(#OBJDOWN)) – the two things come from different scenes, that is to say different times and/or places.
samescene(timeplace(#OBJUP), now) – where ‘now’ is a reserved word, with the predicate meaning that the object represented by #OBJUP is present, in the here and now
There are lots of ways of doing this sort of thing, but something of the sort would cope with a case where #OBJUP is the visual image of a man and #PARTUP is a distinctively coloured shoe, perhaps the important yellow shoes, as in ‘Maigret et l’Homme du Banc’, a story, inter alia, of bench life in inter-war Paris. And where #OBJDOWN is a quite different man but wearing the same kind of yellow shoe, #PARTDOWN, in some different time and place.
A very limited selection of such connections could be carried by LWS conventions, perhaps the shape of the column objects combined with the order of the layers, and understood, in some sense, by the compiler. But this does not seem very satisfactory and we hypothesise that to go further one needs language, or something close to it. To hold more than one thing in mind at the same time one needs the machinery of language to link them together in a serious way, to add some value to their mere juxtaposition.
Descriptive layers
But where are we to put this language and how are we to link it to column objects and through them to layer objects?
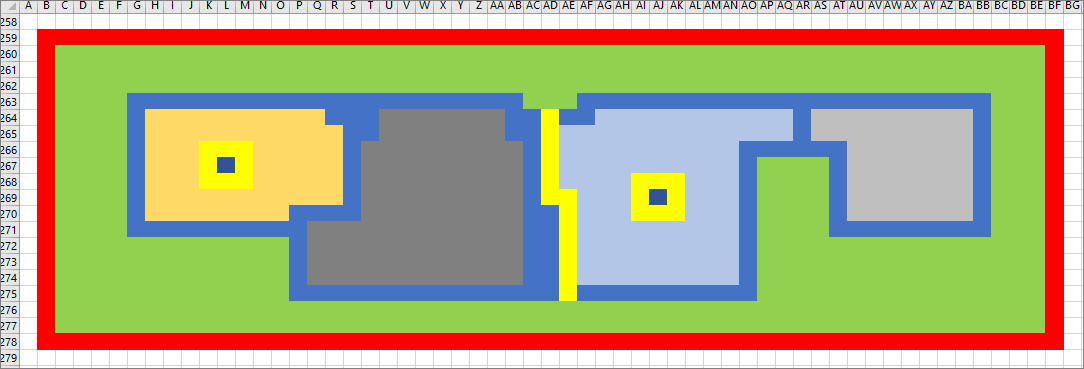 |
| Figure 11 |
Note that along the way we have done away with UP and DOWN. There can only be one column object in any one place in our descriptive layer object, there is exactly one other layer object to be pointed to, not two. Our composite object, rather than saying something like ‘contains(#OBJUP, #OBJDOWN)’, is now saying something like ‘(subject=#OBJCOL object=#OBJCOL verb=contain)’, where we know which column object does for the subject and which does for the object by virtue of their inclusion in the appropriate phrase. No need for identifiers at all – identifiers which seemed a little contrived in a sheet of neurons.
 |
| Figure 12 |
A composite object which corresponds in structure with that at figure 11.
We will be saying rather more about how exactly this saying something might be done in the next paper in this series.
 |
| Figure 13 |
But to go further than that, to replace the vague sense of something below, we add an intermediate layer which would implement four links between the four objects of Figure 7 and the one object of Figure 9 or Figure 10, an intermediate layer which held four descriptive objects of the sort we have in the middle of Figure 12, objects which would say things along the lines that #OBJUP was really just one chunk of the larger #OBDOWN.
 |
| Figure 14 |
Note the three composite objects in the middle layer, with the order border reversed right, reflecting the reversed orientation of the link.
And when activation flows from top to bottom, it takes in those intermediate objects, bringing them into consciousness. Perhaps in the form of very lightly, silently voiced words.
 |
| Figure 15 |
The sort of information which we cannot subsume under the default description at Figure 4 of the three linked layer objects all being images of the same thing. One object being a part of another being different from two objects being different aspects of the same thing, with the difference between, for example, between the taste and smell of something being brought out in the different kinds of texture involved. While here things are different enough that getting the right sense of difference into consciousness needs a bit more help than can be supplied by texture or conventions about links. We need some words, and that is what the second of the two parts of the layer objects of the composite object in the middle can supply.
Things we have not done
We had thought to have focus layers and perhaps focus objects, with the focus serving to guide the meaning of our links, a guiding which might well involve more conventions, conventions rather than explicit content. With ‘active’ being an alternative word to ‘focus’. Ideas which we have dropped for the moment.
We also thought about making a list of different sorts of links and then just coding a link according to what sort of link it was. This one dropped in favour of using something rather closer to ordinary language to do much the same thing, probably involving something like the predicate names suggested above, for example, ‘samekind’.
Conclusions
We have sketched out a new kind of column object which can be used to link layer objects together, layer objects which might come from the same or different layers.
In round terms:
- Column objects are used link layer objects which represent the same thing in some sense or another
- Such links are direct and may involve two or more layer objects
- Usually, a layer object contains at most one column object
- Layer objects which represent different things are linked, indirectly, using a combination of column objects and composite objects
- To this end, composite objects may well contain more than one column object
- These composite objects can also be used to qualify those links, to say something about them.
was invented.
We shall be suggesting ways in which language might be expressed in layer objects in the next paper in this series.
Abbreviations
LWS – local workspace. The proposed vehicle for consciousness. Named for contrast with the GWS – the global workspace – of Baars and his colleagues.
UCS – the unconscious. Most if not all of the rest of the brain, where all the heavy lifting is done.
References
Reference 1: http://psmv3.blogspot.co.uk/2017/01/layers-and-columns.html.
Reference 2: http://psmv3.blogspot.co.uk/2017/03/soft-centred-patterns.html.
Reference 3: https://en.wikipedia.org/wiki/Current_sources_and_sinks.
Reference 4: http://psmv3.blogspot.co.uk/2016/11/on-saying-cat.html.
Reference 5: http://psmv3.blogspot.co.uk/2017/04/a-ship-of-line.html.
Reference 6: http://psmv3.blogspot.co.uk/2017/07/rules-episode-one.html.
Reference 7: http://psmv3.blogspot.co.uk/2017/07/rules-episode-two.html.
Reference 8: https://en.wikipedia.org/wiki/Binding_problem.
Reference 9: http://psmv3.blogspot.co.uk/2017/07/rules-supplemental.html.
Group search key: src.
No comments:
Post a Comment