- Introduction
- Defining binners
- Special bins
- Totals
- Classifications
- Conclusions
- References.
That is to say, on multi-dimensional binning with special reference to LWS-N, introduced elsewhere, for example at reference 1. A tutorial digression which had got rather too big for its original home.
Let X be a population which we wish to investigate, describe or otherwise poke around.
By way of example we have:
- XP: the population of England and Wales on 30th June 2016
- XD: deaths occurring in England and Wales in the period 1st July 2015 to 30th June 2016
- XF: the frames of consciousness experienced by members of the Arsenal football team during the week starting Monday, 2nd October, 2017
- XL: the layers of the frames of consciousness experienced by members of the Arsenal football team during the week starting Monday, 2nd October, 2017
- XH: the moments of consciousness captured during a period of descriptive experience sampling, the technique invented by Hurlburt. See reference 4.
 |
| Figure 1 |
 |
| Figure 2 |
Put another way, we have counted the members of the population, illustrated in Figure 1 into the cross tabulation illustrated in Figure 2. Once upon a time, one used to do this by running one’s finger down something like Figure 1 and counting the rows into something like Figure 2 using five bar gates. Which are illustrated in Figure 3 below.
 |
| Figure 3 |
In Excel, one can simply reproduce the results of that counting on a worksheet, as in Figure 2 above, or alternatively one can use a feature which it calls a pivot table, useful for turning the rows of a population on one worksheet into a cross-tabulation on another. Older readers might remember tools like SPSS which, inter alia, could do much the same thing.
Defining binners
Loosely a binner is something which puts things into bins. A homely example would be the sorting of your household rubbish into four plastic bins outside the back door, according to the recyclability. Amazon sells lots of them.
Less loosely, we define a binner to be a function F from X to the range of integers [1, N], where N is the number of bins, a number which may be in the hundreds (for example, cause of death) but is more usually less than twenty or so (for example, social class). N is called the size of the binner. Binners are usually given names which are more informative than upper case letters like ‘F’, so by way of example, for XP, there might be several binners about age and one of them might be called age05, roughly age in 5 year bands. Another might be called age10, roughly age in 10 year bands. A complication here being that age is time dependant and at some point we will need to choose the date for which age is to be calculated.
Less loosely still, we might define a binner as a pair of functions: F1 from X to C and F2 from C to [1, N], as above, and where C is the list of codes which has been used to code the property of X defined by F1. Maintaining such lists of codes, together with their associated descriptors, can be an important business in its own right. This sort of definition is useful when we have want to have several large binners defined on the same population, all of which look very much the same, say place of birth, place of father’s birth, place of mother’s birth, area of usual residence now and area of usual residence five years ago, and where it often makes sense to use the same code list C for all of them.
Leaving that option aside, suppose we have a number of binners defined on some population X, for example six, called A, B, C, D, E and F. We can then map our population X into a six dimensional array of integers, the sort of thing that you can have in Visual Basic, things defined by statements like ‘define forests(1 to 4, 1 to 8, 1 to 7, 1 to 12, 1 to 17, 1 to 5) as integer’, with the range of each dimension being the size of the corresponding binner.
The numeric part of Figure 2 is an example of a two dimensional array of this sort, very widely used in all kinds of modelling and analysis – with most of the examples that I recall seeing in training manuals being to do with sales figures. And with most of those which I have computed personally being to do with population statistics, otherwise demography. The names of the binners and the names of the bins, that is to say the row and column labels, would usually be kept somewhere else.
We might say that two binners are independent if every combination occurs, at least sometimes. If every cell of our array, if every pigeonhole has occupants. But a lot of the interest will come from looking at pigeonholes where the number of occupants differs from what might be expected from true, statistical independence.
We next define four sorts of binners: numeric, boolean, string and classification. Bear in mind that this is mostly a matter of how one looks at things; which definition seems the best fit to the matter in hand. These four sorts might be exhaustive but they are not exclusive.
Numeric binners
If we have a function from X to R (the set of real numbers), we can define a binner in a natural way by dividing R up into a series of consecutive bins. So if our function is age in years, we can leave negative numbers out of account and our bins might be 0, 1-4, 5-9, 10-14, 15 and over. Noting that if we were talking about age in days counted from birth, in some applications it might make sense to allow negative ages.
Other examples, of wide application, are temperature, weight, length, velocity and area. Noting that with measurements of this sort it is important to use binners appropriate to the accuracy of the measurements. Bins of size 1 are not usually of much use if the measurements are only accurate to around plus or minus 5.
Many numeric binners will be associated with units. An example of a unit, applicable to a set of people, might be age in whole years as at 1st April, 2012, values of which will be non-negative integers.
In some numeric binners, the value of the difference between bin numbers may be significant.
Boolean binners
The special case when our function is to the small set of number, zero and one.
An example might be whether or not an animal has legs. With one for yes and zero for no. Noting that there would have to be a meeting of the rules committee to deal with animals like snakes and whales, which have most of the skeletal machinery needed for legs, without actually having legs; just one example of how what might seem like a nice tidy binner can get untidy.
String binners
In this case our function is from X to S, the set of strings, made up using some particular character set, quite possibly according to some set of rules. For example, the character set might be upper and lower case letter, digits and underscore, and the rule might be starting with an upper case letter and not ending with underscore. Such a character set will usually come with a sort order, in the way that we can sort the letters of the alphabet – in which, deciding what to do about upper and lower case letters can cause some pain. Do we put ‘a’ next to ‘A’ or ‘a’ next to ‘b’?
If our function is one-to-one then that sort order will define an order on X. That is to say for any two members x and y of X, x is either before y, equal to y or after y. We can then define alphabetic bins in the same sort of way as we did for numeric binners. Bin 1 is A to AT, bin 2 is AU to AZ, bin 3 is B and so one. The Oxford English Dictionary is divided into volumes along these lines, with these volumes being much the same as our bins. We call such a binner a alphabetic binner. But note that neither of the binners used in Figure 2 above are alphabetic as some other order seemed more appropriate.
It is not difficult to extend such a definition to allow for the case that the function is not one-to-one. As it will not be, for example, if the set is XP and the function is family name or surname: Brown, Thomson, Blair and so on. Or if X is some set of patients in some hospital and the function is the name of their disease or other complaint.
Classification binners
In this case the binning is defined by a classification, to be further discussed below. Such a binner may well contain less than ten bins, but will often a lot more, sometimes as many as a thousand or so.
The bins of such binners will not usually have a natural order and will have been given one by convention. The difference between bin numbers is most unlikely be significant
An example of a classification binner would be occupation. Other examples are place of usual residence and sex. All of these would be applicable to the set XP. Place and cause of death would be applicable to the set XD.
Multi-coding
In using multi-dimensional binning to describe LWS-N, we shall restrict our attention to binners which are exhaustive and exclusive, that is to say that every member of the relevant population can be assigned to exactly one bin. Put another way, the function defining the binner really is a function, a single valued function, not some other kind of object. We leave aside the clumsy wheeze of defining second order bins for every combination of first order bins, otherwise the power set of reference 5.
But we acknowledge the existence of plenty of improper binners for which this is not true, which are not exhaustive and exclusive.
Excel
By default, when using the Excel pivot table feature, the drill is that every value of a variable defines a bin. Which is fine if one has coded exactly how one wants to analyse one’s data into that data; not so fine otherwise. What happens if one has coded to local authority but want to present management information about regions?
There is, I believe, perfectly good answer, but I have never bothered to get to grips with it.
Special bins
It is often convenient to include one or more of the following special bins in binners.
Other
In the context of a hierarchic classification, it is often convenient to have a residual category of odd and ends to which one does not want to assign individual names. So, for example, for the category carnivores, one might have the four sub-categories cats, dogs, bears and other carnivores.
Not known or not stated
It is sometimes convenient to allow not known or not stated. So in XP there might be people whose age, for one reason or another, we do not know.
Not applicable
It is sometimes convenient to allow not applicable. We might have a population X and a binner about place of usual residence in the UK. We might deal with those who have no such place by leaving them out – but this is apt to confuse. Or by adding ‘Abroad’ or ‘Other’ to the binner – but ‘Not applicable’ is often clearer – and more accurate in that some members of the population may not have a place of usual residence. Think travellers. Or members of the armed forces.
Totals
This being a digression in recognition of my statistical, not to say cross-tabulating past.
From the computer programmer’s point of view, we have already had the complication of where to keep the row and column labels. Another complication is where to keep total and subtotal rows and columns, in the case that they are allowed. Does one keep them with the raw data, in the raw data array or does one create them, just in time, at print time?
One option is to treat totals and subtotals as a special kind of multi-coding, having bins for all the totals and subtotals, into which individuals are counted as we go along.
In any event, generally speaking, statistical packages are good with totals, which need no further specification, but are mostly poor with subtotals, which do need further specification.
 |
| Figure 4 |
Notice that, in principle, any one member of a population could participate in quite a large number of such rows. We might also have disputes about what exactly counts as a country. And I have not yet been able to come up with a sensible population most but not all of which has a country of origin, a population which would justify the inclusion of the ‘not applicable’ bin. The sort of goods sold by transnational companies like McDonald’s, Amazon, Facebook and Google, keen to avoid paying too much tax?
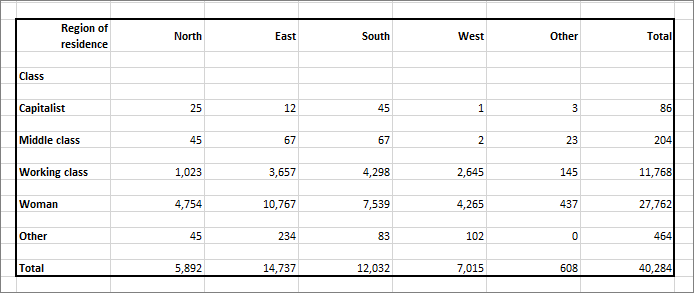 |
| Figure 5 |
Classifications
This being digressive, if not altogether a digression.
People have been classifying complicated things for a long time. Some people classify plants and animals. Other people classify each other. Still other people classify the causes of death in humans.
Large classifications are often organised in a hierarchy. This is usually the case, for example, in the classifications of plants and animals produced by taxonomists. But note that a hierarchy is not the same as an order; put another way a hierarchic classification might have a rich structure but does not usually have a natural order, although such an order may follow from a numeric coding scheme. This is the case, for example, in the Dewey Decimal Classification, used by libraries to code their catalogues and to organise their books onto shelves. Looked after by the people at reference 3.
These classifications are useful in various other ways. First, they are simply interesting, not to say fascinating, and there are plenty of people who do them for that reason alone. A bit like stamp collecting.
More obviously useful, they make it possible to talk to each other about the population in question. So, for example, if I find out something interesting about an animal, it is a lot more interesting, a lot more helpful if I can say what sort of animal it was, so facilitating the investigation of this same something by others. Investigations which might be about why this animal does this something while that nearby animal does not.
Classifications also make it possible to make predictions. If I know what sort of an animal I am looking at, I can make all sorts of good guesses about what is going to happen next. What sort of behaviour that animal is going to exhibit. They also make it possible to find causes: if lots of things called A do something called B after having done something called C, then it is quite likely that C causes B in A.
 |
| Figure 6 |
- They can become an industry in themselves. Fascinating, but expensive and not very useful. In which connection I always think of the CODOT classification of occupation, which is unfair, because at the time it was invented, back in the middle of the last century, it probably made a lot more sense than it does now. See, for example, reference 6. With Figure 6 above showing two of the thousand or so pages of the three volume manual. Notice the five digits of occupational code
- Classifications often start with the idea of assigning any one animal (say) to exactly one category in the classification. But some classifications admit multi-coding, for example, cause of death, applicable to population XD, where it is now much more usual to allow several causes. My uncle died because he smoked, because he had lung cancer, because he had pneumonia, because his heart stopped. The first three are sensible, informative causes of death and the middle two would probably figure on the death certificate. And many classifications can be used with multi-coding: for example, tick all of the places in the list following which you have ever visited. All the brands in the list following which you have ever heard of – this last being he sort of thing which organisations like YouGov are keen on. Analysis of statistics involving multi-coding is much more complicated that analysis of statistics which do not
- There can be too many animals (say) which are difficult to assign to a category. It really is not clear whether this animal should be classified as a small crocodile or as a large newt. The classification does not map onto the real world in a neat and satisfying way.
Turning back to CODOT, one might be interested in both the occupational and industrial structure of the working population, both in what people do and in where they do it. Now if one was a personnel manager one might work in almost any industry and if one was a warehouseman one might work in many industries. But most bricklayers will work in the construction industry, and almost all brain surgeons will work in hospitals. So occupation and industry are correlated. Nevertheless, all of this works through to the consensus that it is usually better to have separate classifications of occupation and industry, thus facilitating multi-dimensional analyses, rather than trying to squash everything into the one classification, although this last might be convenient in particular applications. The two classifications might be quite strongly correlated, but they are about different things and they are organised along different lines.
Sometimes, perhaps because trading standards are involved, standards organisations will feel moved to act in the matter, and produce and promulgate a standard classification to which suppliers of the corresponding products will be expected to adhere. These can sometimes get very complicated.
 |
| Figure 7 |
Certainly one needs to think about what exactly it is that the classification is supposing to be helping us with.
All of which means we need to have a care, to keep a sense of proportion when building our classifications of consciousness, that is to say our lists of states of consciousness, one of which any particular person at any particular time will be in, any particular frame of consciousness, any particular layer of any particular frame of consciousness will be in.
Note that we are not here interested in altered states of consciousness, a phrase associated mainly with use of recreational drugs.
Conclusions
We have exhibited some of the machinery which is used to do multi-dimensional binning, also known as cross-tabulation, with digressions to totalling and to the classification industry.
Most of which is not relevant in the case of LWS-N, where we will only be proposing relatively simple cross-tabulations, with no multi-coding and no totalling. Nevertheless, it was thought useful to exhibit the general lines along which such things are done in other disciplines.
References
Reference 1: http://psmv3.blogspot.co.uk/2017/09/coding-for-colour.html.
Reference 2: http://www.fao.org/fao-who-codexalimentarius/en/.
Reference 3: http://www.oclc.org/en/dewey.html.
Reference 4: http://psmv3.blogspot.co.uk/2017/01/progress-report-on-descriptive.html.
Reference 5: https://en.wikipedia.org/wiki/Power_set.
No comments:
Post a Comment